



Первый раз на Pharmnews.kz?
Войдите, чтобы читать, писать статьи и обсуждать всё, что происходит в мире. А также, чтобы настроить ленту исключительно под себя.
ЗарегистрироватьсяВойдите, чтобы читать, писать статьи и обсуждать всё, что происходит в мире. А также, чтобы настроить ленту исключительно под себя.
Зарегистрироваться















В настоящее время наблюдается научно-технический прорыв в области технологий искусственного интеллекта и машинного обучения. В данной статье описывается использование цифровых инструментов в доклинических и клинических исследованиях с целью оптимизации процессов открытия и разработки лекарственных препаратов. Результаты систематического обзора показали, что применение искусственного интеллекта может способствовать процессам разработки лекарств, делая их более экономичными или полностью устраняя необходимость в клинических испытаниях благодаря моделированию.
По данным ВОЗ, средняя стоимость разработки нового лекарственного препарата (ЛП) составляет от 43,4 млн до 4,2 млрд долларов США. При этом частота регистрации новых ЛП варьирует от 10% до 15%. Применение искусственного интеллекта (ИИ, англ. Artificial intelligence, AI) облегчает анализ больших баз данных и может способствовать выявлению потенциальных молекул для создания ЛП, прогнозирования результатов и оптимизации дизайна клинических исследований. Так, в 2020 году компания Exscientia объявила о первой молекуле, разработанной с использованием ИИ. С помощью программы AlphaFold на базе искусственного ИИ (Google DeepMind) была предсказана структура более 200 миллионов белков. Методы ИИ включают в себя машинное обучение (англ. Machine learning, ML), глубокое обучение (англ. Deep learning, DL), обработку естественного языка (англ. Natural Language Processing, NLP) и генеративные модели. Например, AlphaFold2 (от Google DeepMind) и ESM3 (от Evozyne) используют глубокое обучение для прогнозирования структур почти всех известных белков, меняя понимание о патогенезе заболеваний. Опубликованы промежуточные результаты исследований российских ученых, которые применяли глубокое обучение для обнаружения участка связывания нуклеиновых кислот с целью поиска молекул для создания противовирусных ЛП. Одним из проектов школы стартапов Московской школы управления «Сколково» является EvoPreclinical AI (StemScreen) – платформа цифровизации доклинических исследований молекул. Технологии с использованием ИИ активно используют для решения важных проблем в фармацевтической промышленности и отраслях разработки ЛП. Увеличение количества рандомизированных клинических исследований с большими объемами клинических, лабораторных и других данных определяет необходимость в их систематизации и интерпретации, которые может обеспечить использование ИИ и машинного обучения.
Целью систематического обзора был анализ существующих сценариев применения технологий ИИ в процессах разработки лекарств, а также оценка эффективности и перспективности применения ИИ с точки зрения клинической фармакологии.
Материал и методы
Систематический обзор был выполнен с использованием методологии PRISMA и содержит результаты исследований, опубликованных за период с 2014 г. по январь 2024 г. Поиск источников, производили с использованием баз данных Google Scholar, PubMed, Scopus и Cochrane Central Register of Controlled Trials (CENTRAL), по ключевым словам, [Artificial intelligence] + [Machine Learning] + [Drug R&D]). Критерии отбора исследований: (1) изучение возможности использования ИИ в доклинических и клинических исследованиях; (2) обсуждение потенциала ИИ или машинного обучения в поиске новых химических соединений и мишеней действия; (3) публикация в рецензируемых журналах или других авторитетных источниках, таких как базы данных, принадлежащие правительственным и неправительственным организациям, а также периодические издания, специализирующиеся в области медицинских технологий.
Извлеченные данные были классифицированы по тематическим категориям. Статья предоставляет систематический анализ ключевых факторов, влияющих на динамику развития современных технологий в области доклинических и клинических исследований.
.jpg)
Результаты
В систематический обзор были включены 22 исследования (рис. 1). Доля исследований, проведенных в США, была самой высокой и составила 22,7%. На втором месте по количеству публикаций находится Китай (18,1%), на третьем месте – Великобритания и Канада (по 13,6%). В 50,0% исследований с использованием ИИ и машинного обучения точность метода составляла более 80%, в 33,3% – была менее 80%, а в 16,7% – превышала 90%. Большинство исследований, включенных в систематический обзор, было публиковано в 2019–2021 гг., что, вероятно, отражало необходимость поиска новых мишеней во время пандемии новой коронавирусной инфекции.
Использование технологий машинного обучения в разработке лекарств. Разработка новых ЛП для лечения любого заболевания – это дорогостоящий и длительный процесс, одним из важных этапов которого является поиск новых данных о возможных мишенях действия лекарственных веществ. После определения мишени действия лекарства начинается междисциплинарный этап исследования с подключением методов ИИ и машинного обучения. Данные методы применяются на каждом этапе автоматизированного дизайна лекарств, а их интеграция в процесс увеличивает частоту разработки успешных соединений. Прогнозирование результатов клинических исследований с помощью интегрированных моделей ИИ и машинного обучения позволяет значительно снизить стоимость клинических испытаний, а также повысить их эффективность.
На этапе доклинических исследований важное значение имеет анализ известной информации о патофизиологии заболевания и выбор целевого белка для создания лекарства целенаправленного действия.
Неправильное понимание или недостаток информации о целевом рецепторе в лечении заболевания приводит к финансовым потерям и снижению эффективности процесса разработки ЛП. Эффективность и безопасность ЛП изучаются в рандомизированных клинических исследованиях. На данном этапе можно выявить непредсказуемые эффекты ЛП, не спрогнозированные на доклиническом этапе и связанные с дополнительными мишенями действия лекарственных веществ.
ТАБЛИЦА 1. Исследования, в которых использовалось машинное обучение для разработки и изучения ЛП
|
Авторы |
Год |
Применение |
Методы |
Точность |
|
Jeon J |
2014 |
Поиск лекарств |
Метод опорных векторов (Support Vector Machine; SVM) для определения приоритетных лекарственных мишеней при раке молочной, поджелудочной железы и яичников |
92% |
|
Mamoshina P |
2018 |
Поиск лекарств |
Создание панели тканеспецифичных биомаркеров старения для выявления новых молекулярных мишеней антивозрастной терапии |
80% |
|
Ledneczki I |
2021 |
Поиск лекарств |
Автоматизированное оборудование для быстрого тестирования биологической активности тысяч и миллионов образцов на уровне организма, клеточном или молекулярном уровне |
≥80% |
|
Martínez V Pires D |
2015 |
Перепрофилирование ЛП |
Интеграция информации о заболеваниях, лекарствах и мишенях для оптимизации использования существующих групп ЛП |
80% |
|
Pires D |
2021 |
Поиск лекарств |
Количественная оценка влияния мутаций на сродство белков к малым молекулам при генетических заболеваниях и возникновение лекарственной устойчивости |
76% |
|
Kaminskas L |
2019 |
Разработка лекарств |
Разработка и уточнение конструкции дендримера перед более трудоемкими и дорогостоящими испытаниями in vivo |
80% |
|
Montanari F |
2019 |
Разработка лекарств |
Прогнозирование профилей взаимодействия малых молекул с транспортерами элиминирующих органов |
59/87% |
ТАБЛИЦА 2. Исследования, в которых использовались большие данные (англ. Big Data) для разработки ЛП
|
База данных |
Методы |
|
PubChem |
Общедоступный ресурс больших данных, включая большинство лекарств и химических соединений |
|
ChEMBL |
Более 2,2 млн соединений, протестированных против более 12 000 мишеней; содержит данные об активности 15 млн пар таргетных соединений |
|
DrugBank |
12110 записей о лекарствах, включая 2553 малых молекул, 1280 биотехнологических (белковых/пептидных) препаратов, 130 нутрицевтических препаратов и более 5842 экспериментальных препаратов |
|
DrugMatrix |
Данные об экспрессии генов из тканей крыс, более 600 препаратов, в основном нацеленных на несколько конкретных органов (например, печень). |
|
Therapeutic Targets Database |
База данных об известных и изученных терапевтических белках, мишенях и различных заболеваниях. |
|
The Cancer Genome Atlas |
Клинические данные о различных видах рака человека, геномных мутациях, экспрессии мРНК, микроРНК, метилировании и т.д. |
|
Cancer Cell Line Encyclopedia (CCLE) |
Данные об экспрессии генов, количестве хромосомных копий и параллельном секвенировании |
|
Search Tool for the Retrieval of Interacting Genes/Proteins |
База данных об известных и прогнозируемых белковых взаимодействиях. |
Использование алгоритмов машинного обучения, начиная с первых этапов клинического исследования, позволяет прогнозировать «скрытые» эффекты и возможные проблемы при воздействии ЛП на ту или иную мишень.
P. Momoshina и соавт. (2018) применили несколько методов машинного обучения, включая нейронные сети, для создания панели тканеспецифичных биомаркеров старения мышц человека. Было показано, что биомаркеры старения могут быть использованы для выявления новых молекулярных мишеней для замедления процессов старения (anti-age therapy).
За последние десять лет были разработаны методы высокопроизводительного скрининга (англ. HighThroughput Screening, HTS). HTS представляет собой автоматизированное определение биологической активности множества разнообразных соединений и выявление среди них соединений-лидеров с наилучшими характеристиками в больших сериях однотипных молекул. Существующие методы HTS обычно сочетаются с роботизированными методами и требуют достаточно небольшого количества ресурсов для тестирования библиотеки химических соединений. Данные HTS постоянно пополняются и вносят вклад в общую систему больших данных. Например, HTS позволяет выявить новые мишени действия и оценить возможные изменения активности ферментов при применении аллостерических ЛП, которые связываются с рецептором и изменяют его ответ на лиганды. Разработка данных ЛП осуществляется с использованием вычислительных подходов к прогнозированию аллостерических взаимодействий и мониторингу потенциальных аллостерических модуляторов для изменения конформации и активности многообразных аллостерических ферментов.
Применение больших данных в процессе разработки лекарственных препаратов. Термин «большие данные» (англ. Big Data) описывает большие неупорядоченные объемы данных, которые настолько обширны, что их слишком сложно обработать с помощью радиционных инструментов анализа. Большие данные получают все большее применение в клинических исследованиях и других областях исследований с использованием биологических данных. Огромный объем данных генерируется в процессе разработки и исследования лекарственных веществ. Необходимость в новых вычислительных методах, включая интеллектуальный анализ/генерацию данных, контроль, хранение и управление, приносит новые проблемы и возможности для исследований (табл. 2).
За последние десятилетия начаты несколько проектов по обмену данными параллельно с развитием методов HTS в различных скрининговых центрах. Например, PubChem является публичным хранилищем химических соединений и их биологических свойств. За 15 лет количество соединений в PubChem увеличилось до 119 млн к 2024 году. За тот же период количество скрининговых исследований биоактивности, которые были депонированы в PubChem, увеличилось до 295 млн в 2024 году (https://pubchem.ncbi.nlm.nih.gov).
Огромное количество данных PubChem по биоактивности, которые обновляются ежедневно, представляет собой общедоступный ресурс больших данных, включая большинство лекарственных веществ. База данных ChEMBL содержит большое количество вручную отобранных данных из источников литературы. В настоящее время база данных ChEMBL состоит из более чем 2,4 млн соединений, протестированных против более 15000 мишеней, в результате чего поступают данные об активности для более 20 млн пар таргетных соединений (https://www.ebi.ac.uk/chembl/).
Несколько других источников данных специально разработаны для анализа соединений на доклинических этапах, а также для зарегистрированных ЛП. Например, DrugBank (https://www.drugbank.ca) является общедоступной базой данных, содержащей все одобренные лекарства с их механизмами действия, лекарственными взаимодействиями и соответствующими эффектами. Последняя версия DrugBank, выпущенная в марте 2024 года, содержит 17181 записей о лекарствах, включая 2787 одобренных малых молекул, 1639 одобренных биопрепаратов (белковых/пептидных), 135 нутрицевтических ЛП и более 6722 экспериментальных ЛП.
DrugMatrix https://ntp.niehs.nih.gov/results/drugmatrix/index.html), с другой стороны, фокусируется на токсикогеномических данных о ЛП, использование которых позволяет сократить сроки оценки потенциальной токсичности ксенобиотика. В настоящее время DrugMatrix содержит крупномасштабные данные об
экспрессии генов в тканях крыс и более 600 ЛП, большей частью нацеленных на несколько основных органов (например, печень).
ТАБЛИЦА 3. Исследования, в которых использовались элементы искусственного интеллекта и алгоритмы машинного обучения для разработки ЛП в доклинических исследованиях
|
Авторы |
Год |
Технология |
Применение |
Методы |
Точность |
|
Cui R |
2021 |
Глубокое обучение |
Поиск лекарств |
Прогнозирование растворимости молекулярных соединений по сравнению с другими моделями, не основанными на ИИ |
- |
|
Daynac M |
2015 |
Искусственные нейронные сети |
Поиск лекарств |
Прогнозирование антимикробных свойств различных молекул |
>70% |
|
Pu L |
2019 |
Искусственные нейронные сети |
Поиск лекарств |
Прогнозирование степени токсичности синтетических и биологических соединений |
72% |
|
Rifaioglu A |
2020 |
Глубокое обучение, нейронные сети |
Разработка лекарств |
Прогнозирование взаимодействия препарата с мишенью |
≥80% |
|
Spiegel J |
2020 |
Генетические алгоритмы |
Разработка лекарств |
Программа с открытым исходным кодом для автоматизированного дизайна лекарственных соединений и оптимизации их компонентов |
- |
|
Jarada T |
2021 |
Глубокое обучение; искусственные нейронные сети |
Разработка лекарств |
Платформа SNF_NN, в которой новые взаимодействия между лекарствами и болезнями предсказываются на основе использования данных о сходстве между ЛП и между заболеваниями и известными взаимодействиями ЛП и заболеваний |
80% |
|
Cao X |
2020 |
Искусственные нейронные сети |
Разработка лекарств |
Система прогнозирования лекарственных взаимодействий и взаимодействий “лекарство-мишень” |
90% |
При анализе больших данных возникают определенные проблемы, связанные с объемом данных и скоростью его увеличения, разнообразием источников и неопределенностью данных. Наборы данных, доступные для разработки лекарств, особенно в фармацевтической промышленности, могут включать в себя множество соединений (например, от 100 000 до нескольких миллионов), которые были протестированы на многих моделях, а традиционные подходы к моделированию не всегда подходят для работы с такими данными. Кроме того, неопределенность или отсутствие части данных может служить препятствием для их использования. К сожалению, при переходе от исследований in vitro к исследованиям in vivo резко возрастают разнообразие и неоднородность полученных данных, что объясняется более сложными биологическими механизмами, такими как реакции организма на лекарства (рис. 2). Данная проблема больших данных потребовала разработки новых вычислительных подходов к обработке объемных и многомерных источников данных для прогнозирования эффективности ЛП и нежелательных реакций у животных и/или людей. Рост вычислительных мощностей и разработка инновационных методов в области ИИ могут использоваться для реформирования процессов исследования и разработки лекарств. В последние годы произошел значительный рост уровня цифровизации данных в фармацевтической промышленности. Их эффективное получение, анализ и применение для решения сложных клинических проблем является актуальной задачей. Системы на основе ИИ могут обрабатывать огромные объемы информации, а использование алгоритмов машинного обучения позволяет повысить эффективность и производительность таких систем. Основное использование ИИ в данном направлении заключается в прогнозировании свойств ЛП, что может снизить потребность в клинических исследованиях и количестве их участников, что будет выгодно как с финансовой, так и с этической точки зрения.
Рис. 2. Проблемы моделирования методами искусственного интеллекта при разработке ЛП
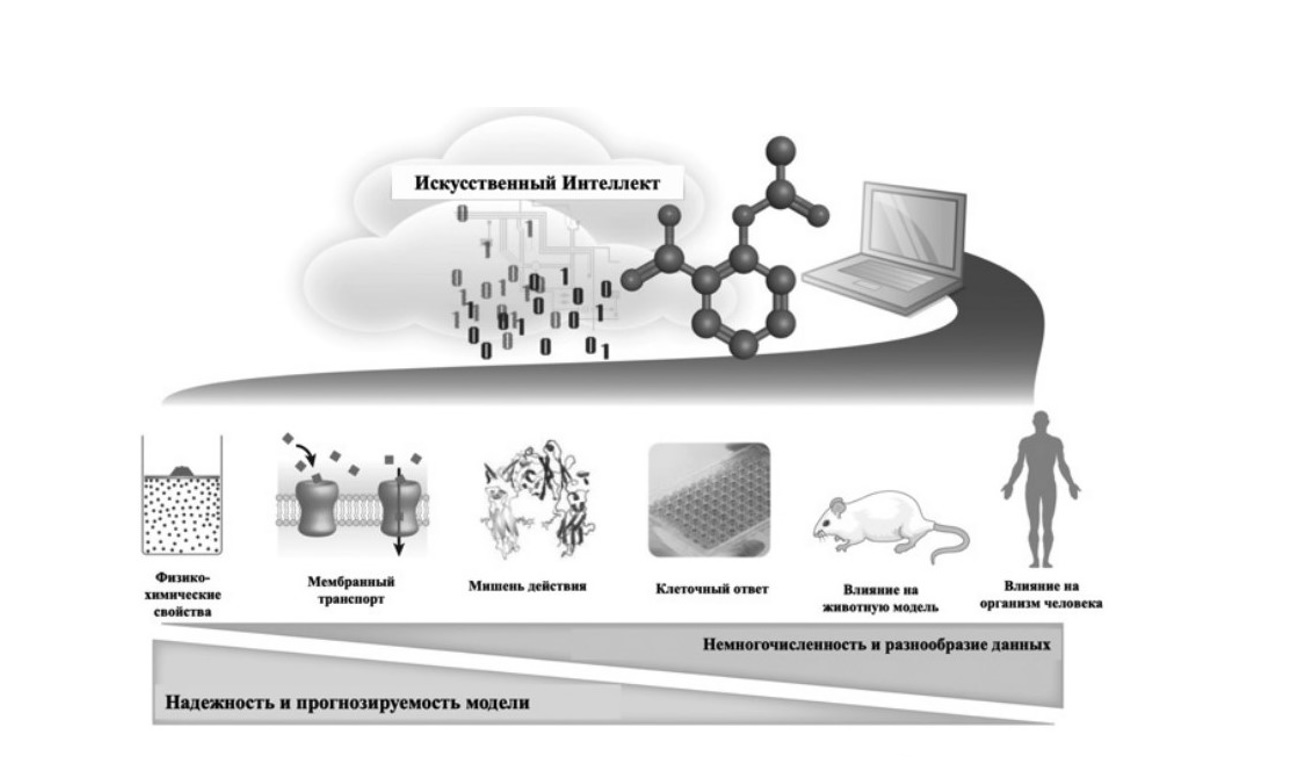
R. Cui и F. Zhu (2021) показали, что использование нейронной сети ResNet позволяет точнее предсказать растворимость молекул по сравнению с другими моделями, не основанными на ИИ. Это доказывает, что ИИ можно интегрировать в процедуру разработки лекарств для повышения ее эффективности. Целью исследования M. Daynac и соавт. (2015) было определить возможность использования искусственных нейронных сетей для прогнозирования антимикробных свойств различных молекул с целью упрощения и повышения надежности и скорости процесса поиска новых антибактериальных ЛП. Предложенная авторами искусственная нейронная сеть точно предсказала более 70% антимикробной активности эфирных масел в отношении исследуемых микроорганизмов в пределах максимального диапазона погрешности 10 мм с использованием диско-диффузионного метода микробиологического тестирования. Также удалось спрогнозировать эффекты двух или трех молекул одновременно, что позволяет сократить общее время анализа исходных данных. Возможность использования программы eToxPred для прогнозирования степени токсичности различных синтетических и биологических соединений с целью ускорения процесса разработки и устранения необходимости в проведении клинических исследований показано в исследованиях L. Pu и соавт. (2019). Модель на основе искусственных нейронных сетей позволяла предсказать токсические свойства соединений более чем в 72% случаев с общей частотой ошибок всего 4%. Этого достаточно, чтобы рассматривать данную платформу как потенциальную альтернативу исследованиям токсичности ЛП. Обсуждение Разработка и клинические исследования ЛП представляют собой длительную, дорогостоящую и трудоемкую процедуру, которая должна соответствовать строго регламентированным нормативно-правовым требованиям. Большой интерес в этой области вызывает использование ИИ для внедрения инновационного моделирования на основе меняющихся и неоднородных больших массивов данных о лекарствах и потенциальных молекулах. Такие подходы как, глубокое обучение, могут применяться для оценки эффективности и безопасности молекулярных соединений на основе моделирования и анализа больших данных. Данные модели обеспечивают оптимальную работу с большим массивом данных на всех стадиях разработки лекарств, начиная от поиска молекул, стадий доклинических, клинических исследований до использования лекарственных препаратов в реальной клинической практике. Новые методы интеллектуального анализа и управления данными оказывают значительную поддержку недавним исследованиям в области моделирования в медицине. J. Jeon и соавт. (2014) предложили использовать метод опорных векторов (англ. Support Vector Machine; SVM) для определения приоритетных лекарственных мишеней при раке молочной железы, поджелудочной железы и яичников. Первоначально был создан классификатор, который объединяет различные геномные и систематические наборы данных для определения возможных мишеней, специфичных для злокачественных опухолей указанной локализации. Затем были разработаны стратегии подавления этих мишеней и отобран набор мишеней, которые поддаются ингибированию малыми молекулами, антителами и синтетическими пептидами. Подводя итог, можно сказать, что достижения в области ИИ в эпоху больших данных помогают проложить путь к рациональной разработке и оптимизации ЛП, что окажет значительное влияние на процессы открытия и исследования новых лекарственных средств и, в конечном итоге, на систему здравоохранения в целом. Сочетание машинного обучения, особенно глубокого, с человеческими навыками и опытом может стать лучшим способом работы с многочисленными базами данных. Значительные возможности интеллектуального анализа данных в конечном итоге определяют новую парадигму развития цифровой медицины. Интеграция ИИ и больших языковых моделей (Large language models, LLM), предварительно обученных на огромных объемах данных, открывает новую эру в развитии клинической фармакологии. Применение данных технологий способно ускорить открытие лекарств, оптимизировать процесс клинических исследований и персонализировать подходы к лечению пациентов. Однако быстрое развитие и использование ИИ и LLM опередило развитие соответствующей нормативной базы, что привело к возникновению регуляторного вакуума, который создает серьезные проблемы с этической точки зрения. Текущая нормативно-правовая база плохо приспособлена для решения проблем, связанных с использованием ИИ в клинической фармакологии. Существующие правила лишь косвенно затрагивают вопросы, связанные с ИИ и LLM. Проблемы риска неправильного использования данных пациентов подчеркивают острую необходимость в совершенствовании регуляторного надзора и разработке нормативной базы, специально регулирующей использование ИИ и LLM в клинической фармакологии на основе принципов прозрачности, подотчетности и безопасности. Она должна включать конкретные положения, которые помогут предотвратить неправомерное использование ИИ и LLM. Необходимо также предпринять усилия по продвижению этических норм и стандартов в сообществах ИИ и клинической фармакологии. Этичное использование ИИ в клинической фармакологии – это не просто вопрос соблюдения нормативных требований, но и решающий фактор в обеспечении безопасности и благополучия как пациентов, так и общества в целом [29]. Заключение Предиктивные и аналитические возможности технологий ИИ превосходят традиционные методы поиска новых молекул для разработки ЛП. Сегодня данные технологии наиболее активно развиваются в США, Китае и странах Европы. Точность большинства алгоритмов остается недостаточной (менее 90%), поэтому при использовании технологий машинного обучения необходима постоянная оценка моделей и актуализация информации для обеспечения их более высокой точности. Однако несмотря на ограничения интеграция ИИ в рабочие процессы и более широкое его использование может снизить затраты на разработку новых ЛП и повысить ее эффективность. Анализ больших данных и моделирование способствуют сокращению времени на поиск потенциальных молекул при разработке лекарств. Применение ИИ позволяет также уменьшить затраты на исследования, поскольку он помогает эффективно сортировать и анализировать огромные массивы данных, выявляя наиболее перспективные соединения и минимизируя количество неудачных исследований.
И.Р. Свечкарев, А.В. Гусев, А.С. Колбин
ФГБОУ ВО «Первый Санкт-Петербургский государственный медицинский университет имени И.П. Павлова», ФГБУ «Центральный научно-исследовательский институт организации и информатизации здравоохранения» Минздрава РФ, Москва, К-Скай, Петрозаводск, Санкт-Петербургский государственный университет, Санкт-Петербург.
Список литературы - в редакции.






Адрес редакции:
г. Алматы, ул. Жандосова, 98, БЦ "Навои Тауэрс",
6 этаж, офис 603
тел.:+7 727 385 85 69,
+7 708 312 70 75,
+7 708 605 47 73,
+7 747 409 77 56
Система оплаты: 





{kind=link}
Комментарии
(0) Скрыть все комментарии